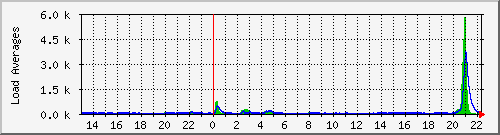
Ok – some real-life critical experience today.. one of our web servers notifies us (thanks to csf / lfd firewall ) that the server has had a high load for greater than 5 minutes. I get logged in and see the 5,10 & 15 minute load average exceeding 30 and this server normally runs at a load of <1
Here’s the MRTG Graph of the load:
A quick look at top showed me approx 15 httpd (apache) processes maxxing out the CPU. Now, it’s a shared server with hundreds of Virtual hosts and we need to find out which site is causing the issue.
Now, here’s the fun part – mod_status can help us out here, if we have it enabled.
/etc/init.d/httpd fullstatus or /etc/httpd/bin/apachectl fullstatus
should give you some output like
Srv PID Acc M CPU SS Req Conn Child Slot Host VHost Request
0-0 4419 0/403/403 _ 70.45 5 9 0.0 2.20 2.20 220.181.19.162 www.domain.com GET /096.htm HTTP/1.1
1-0 4420 0/270/270 _ 7.97 4 20 0.0 1.33 1.33 66.249.72.228 www.domain.com.au GET May24.htm HTTP/1.1
2-0 4421 2/274/274 K 8.49 2 319 0.0 1.03 1.03 66.249.72.228 www.cdomain.com.au GET /refrigeration/
3-0 4422 1/334/334 K 13.37 1 43 0.0 1.70 1.70 66.249.72.228 www.domain.com.au GET /image.php?number=11 HTTP/1.1
4-0 4423 0/211/211 _ 28.61 15 277 0.0 0.71 0.71 203.94.138.108 www.domain.com POST /mbalert.php HTTP/1.1
This obviously, isn’t the data from the moment the issue appeared but it was clearly obvious that it was one site causing the issue. I was a bit surprised because the majority of our servers run an Apache module called mod_evasive which in their own words does:
mod_evasive is an evasive maneuvers module for Apache to provide evasive action in the event of an HTTP DoS or DDoS attack or brute force attack. It is also designed to be a detection and network management tool, and can be easily configured to talk to ipchains, firewalls, routers, and etcetera. mod_evasive presently reports abuses via email and syslog facilities.
Detection is performed by creating an internal dynamic hash table of IP Addresses and URIs, and denying any single IP address from any of the following:
Requesting the same page more than a few times per second
Making more than 50 concurrent requests on the same child per second
Making any requests while temporarily blacklisted (on a blocking list)
Anyway, after a recent upgrade the server didn’t have mod_evasive installed. We know which site is causing the issue but the customer who owns the site is one of our best customers and it’s a Joomla site that we helped develop, so it’s important to keep it up and fix the issue.
Now, I need to know WHY the site is chewing so much CPU.
Tool #1. iftop – is like top for interface traffic. It shows local ip and port, remote ip and port and a graphic representation of the immediate traffic for the connection as well as totals and averages.
– are we seeing huge amounts of excessive traffic to the server, as in a DDOS attack? No let’s move on to the next tool.
Tool #2. apachetop – Apache top is like ‘top’ but for apache. The problem with it is that it needs to look at your server log and in this case, the Virtual Server has it’s own log, so we had to know which Website it was before using apachetop.
It’s most basic syntax is: apachetop -f /path/to/virtual_server.log
Ok, now we are able to see that the issue is from a web crawler called “webwombat” – An Australian search engine (that I have never heard of)
So, we grab the IP addresses of their bots and add them to the deny file for the firewall.. this is temporary to stop the load while we fix the underlying problem.
Tool #3. strace -What is strace?
strace is a system call tracer, i.e. a debugging tool which prints out a trace of all the system calls made by a another process/program.
strace is a hard tool to use with anything that spawns child processes. Because it only attaches itself to the process you tell it to and who knows which process is going to serve the next request? I guess you could change your httpd.conf to only run a single child process but for myself, I setup a small script with an infinite loop using wget or curl that calls a page of the site I am trying to catch. I then attach strace to one of the apache processes I see in top:
strace -p <processid>
and with my script running, within a minute or two I will see my chosen pid serve the request to the client (the script) and as it completes, I kill Ctrl-C out of strace (ensure you have a long buffer in your terminal window)
As the site in question is served, I noticed a very strange pattern that I didn’t see with other sites being served and here is a section of the output from strace:
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\213\0\0\25”, 4) = 4
read(12, “\003568\2-1\n/uniforms/:index.php?opt”…, 139) = 139
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\253\0\0\26”, 4) = 4
read(12, “\003555\2-1)/refrigeration/glass-doo”…, 171) = 171
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\237\0\0\27”, 4) = 4
read(12, “\003554\2-1\35/refrigeration/chest-fre”…, 159) = 159
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\237\0\0\30”, 4) = 4
read(12, “\003553\2-1\36/food-preparation/meat-s”…, 159) = 159
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\271\0\0\31”, 4) = 4
read(12, “\003552\2-1:/food-display/hot-food-d”…, 185) = 185
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\242\0\0\32”, 4) = 4
read(12, “\003551\2-1 /food-preparation/spiral”…, 162) = 162
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\242\0\0\33”, 4) = 4
read(12, “\003550\2-1\37/uniforms/hospitality-cl”…, 162) = 162
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\240\0\0\34”, 4) = 4
read(12, “\003549\2-1\36/used-equipment/cash-reg”…, 160) = 160
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\242\0\0\35”, 4) = 4
read(12, “\003548\2-1 /miscellaneous/bag-seale”…, 162) = 162
setsockopt(12, SOL_SOCKET, SO_RCVTIMEO, “\2003\341\1\0\0\0\0”, 8) = 0
read(12, “\247\0\0\36”, 4) = 4
it was rows and rows of that. I go and take a look at the site. It has >700 items in a catalogue style layout. There were two issues:
Problem 1. The site is using SWMenu Pro – the client had requested that all 700 items in the catalogue be accessible from the flyout javascript menu and so, of course the client wasn’t talked out of his madness instead the developers complied – it currently pumps out >150kb of HTML for each page that loads. PHP was creating it for each page load. Fortunately has a caching option *that wasn’t turned on* – so you know what I did? Now the menu is cached, it no longer has to recreate it each time. That was half our problem fixed. Page load times dropped from approx 8 seconds, down to about 4-5 seconds.
Problem 2. OPEN SEF – I actually love Open SEF because it prevents you being a prime target to fresh Joomla security exploits by hackers using google. The problem in this case is that it is converting over 700 url’s on each page load. CPU killer number 2. This is a harder issue to fix but SWMenu has some good functionality that is just too hard to explain in writing.. but put simply, it allows you to manage an infinite amount of menu levels in a very granular way. I don’t feel I need to get into this just now but at least it’s there if we have further issues.
I watched Googlebot go over the site and load stayed very low and it’s certainly not the kind of site that will get on Digg, Reddit or Slashdot, so I am satisfied with that for now.
The only thing that needs to be done, is to install mod_evasive, this would prevent bots like webwombat from being able to make too many simultaneous requests. If you DO run mod_evasive be aware that you want to be careful with it. Some things to watch out for:
- Make sure mod_evasive isn’t blocking google. Your customers wouldn’t be happy for the traffic they are losing.
- If you do any load testing, make sure you disable mod_evasive before doing so
Good luck.. and kudos to all those who wrote the great tools above.
Technorati Tags: apache, mod_status, mod_evasive, apachetop, strace, iftop, troubleshooting, joomla
Powered by ScribeFire.